Google показали, що їхній квантовий комп'ютер Sycamore може виявляти і виправляти свої обчислювальні помилки так, що шум спадає експоненціально залежно від числа кубітів. Новий код корекції при збільшенні числа кубітів від 5 до 21 знижує ймовірність помилки в 100 разів. Це необхідно для масштабування квантових комп'ютерів та дасть змогу створити процесор зі значно більшою кількістю кубітів, необхідних для обчислень. Робота команди опублікована у Nature.

Процесор Sycamore / Google
Як помиляються квантові комп'ютери?
Головною і найбільш відомою особливістю квантових технологій є неможливість спостерігати за системою так, щоб не викликати у ній неконтрольованих збурень. Система неминуче контактує із зовнішнім середовищем і піддається явищу декогеренції, після чого вже не дає нам отримати інформацію з неї. Але ми не можемо використовувати квантову систему для зберігання і надійної обробки інформації повністю ізольованою від зовнішнього світу. Нам потрібно керувати нею, зчитувати оброблену кубітами інформацію. Загалом нам потрібно навчитися захищати кубіти як від звичайних помилок перевороту бітів (коли стан кубіта змінюється з 1 на 0 або навпаки), так і від помилок перевороту фази (коли змінюється знак суперпозиції).
Тож для реалізації потенціалу квантових обчислень потрібно якимсь чином знизити кількість помилок принаймні до значення ¹⁰⁻³, однак поки сучасні квантові платформи можуть забезпечити всього ¹⁰⁻¹⁵. Через це американський фізик-теоретик Джон Прескіл (John Preskill) назвав сучасне покоління квантових процесорів «шумними квантовими комп'ютерами середнього розміру». Вони мають від 50 до кількох сотень кубітів, але недостатньо розвинені, щоб забезпечити відмовостійкість, і не досить великі, щоб досягти квантової переваги. Також потрібно дбати про так звану якість кубітів — точність здійснених над ними операцій (вентилів). Наприклад, для квантових комп'ютерів із захопленими іонами чи надпровідними кубітами, частота помилок на вентиль перевищує рівень 0,1 відсотка.
Як виправляти їхні помилки?
Високий рівень помилок звісно можна компенсувати й одним із поширених способів є розробка кодів корекції, які використовують певне розташування кубітів так, щоб вони працювали на виявлення помилок один одного. Популярним підходом є використання надлишкових кубітів. Так логічну інформацію кубіта розподіляють між кількома кубітами для відстеження цієї інформації з метою виявлення і виправлення помилок. Система порівнює між собою кілька копій одного і того ж стану кубіта, а якщо знайдеться невідповідність, то це скаже про те, що сталася помилка. Однак необхідність використання додаткових кубітів помітно збільшує їхню загальну кількість, що ускладнює технічну реалізацію — може знадобитися більше 1000 таких на кожен корисний «логічний» кубіт. У Google вирішили поекспериментувати зі своїм 54-кубітним процесором Sycamore та перевірити на ньому дві різні схеми корекції помилок: з повторенням і поверхневий код. Вчені шукали, який з них зможе краще справитися зі змінами у кубітів стану та фази.
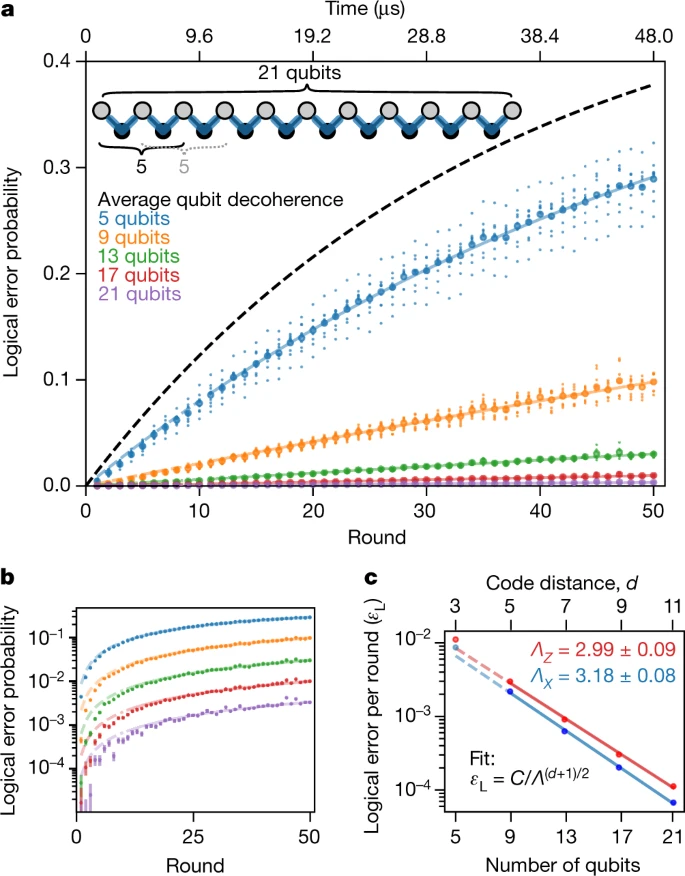
Імовірність логічної помилки в порівнянні з кількістю раундів виявлення та кількістю кубітів для виявлення перевороту фази. Zijun Chen et al. / Nature, 2021
Що придумали у Google?
У всіх квантових процесорах кубіти пов'язані зі своїми сусідами. Є багато способів організувати ці сполуки. У свої роботі розробники для першої схеми розташували їх ланцюжком, а для другої — шахівницею. У першій всі внутрішні кубіти пов'язані з чотирма сусідами, де кожен кубіт відстежує обох своїх сусідів і перевіряє зв'язок на парність. Тобто ланцюжок розташований не по прямій, а таким чином, щоб кубіти опинялися поруч. Так якщо який-небудь з них має єдину помилку, вимірювання цього біта виявлять її та повідомлять систему. Однак, таким чином логічний кубіт захищений або від перевороту стану, або від перевороту фази. Ця схема не спрацює, якщо одночасно виникнуть два різних типи помилок одночасно поруч. Друга стратегія, де кубіти розташувалися у шаховому порядку, може виявляти обидва типи помилок одночасно, що забезпечує більш надійний захист. Але вона не вкаже на кубіт, який видає помилку і все ж потребує більшої кількості кубітів. До першої схеми вчені залучили 21 кубіт, що лишалися когерентними 15 мікросекунд, для другої — всього сім, які не втратили когерентність за 19.
Так у двовимірну сітку надпровідних кубітів процесора розробники спершу вбудували одномірний повторюваний код, що показав експоненціальне придушення помилок перевороту бітів або перевороту фази. Причому зменшуючи логічну помилку за раунд більш ніж в 100 разів при збільшенні кількості кубітів з п'яти до 21. Важливо відзначити, що процес був стабільним протягом 50 циклів.