Британські розробники з DeepMind показали штучний інтелект DeepNash, що може грати у гру «Стратего». Він досяг рівня професійних гравців та увійшов у трійку кращих, самостійно навчившись блефу та непередбачуваності у своїй ігрові стратегії. DeepNash самостійно освоїв правила гри, а ключем до успіху стала здатність передбачати ходи суперників. Присвячена системі стаття доступна у журналі Science, а коротко про DeepNash розповідає DeepMind у своєму блозі.

Приклад ігрового поля у «Стратего». Rod Zadeh / Shutterstock
Що це за гра?
«Стратего» — це популярна настільна гра, яка полягає у тому, щоб захопити прапор супротивника чи його фігури. Раунди можуть розтягуватися на сотні ходів, які неможливо розбити на підзадачі. Гравець має приймати на основі великої кількості окремих дій інших гравців без очевидного зв'язку між дією і результатом. Гра має 10 535 можливих ходів, що більше ніж в техаському покері та ґо, а також вимагає від гравця обдумування більш як 1 066 можливих позицій на початку гри, тоді як в тому ж покері є всього 103 можливі пари карт.
Тому «Стратего» довго була недосяжною для штучного інтелекту, а існуючі методи ледь досягали аматорського рівня гри. Однак розробникам з DeepMind вдалося підкорити і її штучному інтелекту.
Як навчити в неї грати ШІ?
Оскільки звичний для штучного інтелекту пошук ходів в іграх методом Монте-Карло був би для цієї гри неефективним через велику кількість можливих ходів, ціллю розробників було навчити DeepNash стратегіям рівноваги Неша. Ця тактика дозволить передбачати дії суперників та орієнтуватися на свої прогнози для наступних ходів. При цьому навчання відбувалося без моделей, тобто DeepNash не намагався моделювати можливі ходи своїх опонентів, що в рамках цієї гри є взагалі неефективним. Розробникам же вдалося навчити DeepNash йти на нетривіальні компроміси, блефувати і ризикувати, коли це необхідно.
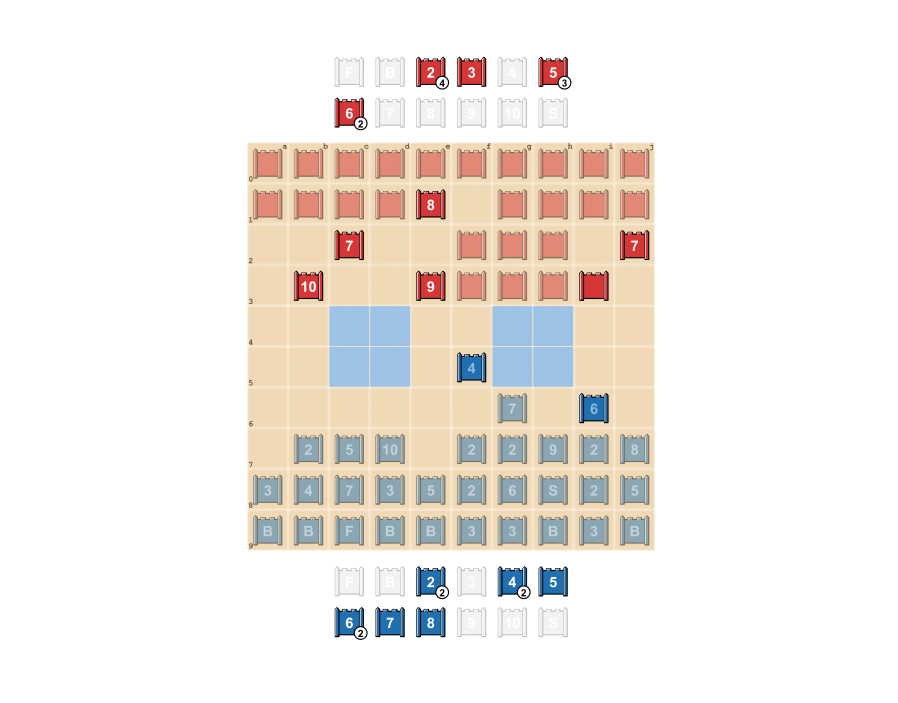
DeepNash (синій) уже знайшов багато найпотужніших фігур свого супротивника, зберігаючи при цьому власні ключові фігури в секреті. DeepMind
Так, наприклад, DeepNash, ризикуючи лише незначною фігурою, може виманити та знищити критичну фігуру супротивника. Або не використовувати якусь більш вигідну на певному етапі фігуру, щоб не розкрити її для противника. Розробники сподіваються, що їхня стратегія розширить можливості штучного інтелекту, що дозволить застосувати його в реальних, а не ігрових ситуаціях з високою непередбачуваністю. DeepNash поборовся з найкращими гравцми у «Стратего» на платформі для гри в неї онлайн Gravon. Він увійшов у трійку карщих гравців із коефіцієнтом перемог в 84 відсотки.
Більше про те, як ігри стали способом вимірювати прогрес в області штучного інтелекту, ми розповідали у нашому тексті «Ігри, у які грають роботи».
Що вміє ШІ DeepMind?
🎮 Наприклад, MuZero може пограти в шахи, ґо та 57 ігор на приставці Atari
🌧️Також у DeepMind є штучний інтелект для прогнозу погоди, зокрема опадів
🪰 AlphaFold передбачив структуру 98,5 відсотка людських білків та плодової мушки
📜А нейромережа «Ітака» вміє відновлювати втрачені фрагменти давньогрецьких текстів