Новий алгоритм від британських розробників штучного інтелекту DeepMind під назвою «Ітака» перечитав понад 170 тисяч розшифрованих давньогрецьких текстів і допоміг відновити втрачені фрагменти з точністю до 62 відсотків. Крім цього нейромережа змогла розподілити тексти по регіонах та навіть датувати їх з похибкою до 30 років. «Ітака» генерує кілька варіантів втрачених фрагментів тексту, з яких дослідники зможуть обрати підхожий. DeepMind опублікували вихідний код «Ітаки» у відкритий доступ та навіть запустили безкоштовну інтерактивну версію. Детальніше про розробку вчені розповіли у статті, опублікованій у Nature.

Відновлення пошкодженого напису з записом указу від 485/4 року до нашої ери щодо Афінського Акрополя. IG I3 4B / Wikimedia Commons
Як розшифровують давні тексти?
Дослідженню стародавніх написів, вирізьблених на твердих матеріалах, як-то камінь, кераміка і метал, присвячена наука епіграфіка. І хоча до нашого часу збереглися тисячі таких пам'яток, часто спеціалістам у цій галузі доводиться працювати з фрагментами, відновлюючи тексти за доступними частинами. У такому випадку вчені шукають текстові і контекстуальні паралелі: відновлюють втрачені графеми за відомостями про мову оригіналу та історичним контекстом, враховуючи час і місце появи пам'ятки.
Але навіть така інформація в арсеналі дослідника може не бути запорукою успіху, адже пам'ятки у ході історії могли перевозитися і продаватися, а радіовуглецевий аналіз часто неможливий через сам матеріал, на якому знайдено текст. Відомостей про давні мови може бути недостатньо, тому у відновленні текстів часто доводиться звертатися до значних узагальнень.
Втім, для нейромереж завдання з зіставлення різної інформації є набагато простішим, адже вони добре вміють виявляти та використовувати складні статистичні закономірності у величезній кількості даних. І збільшення їхніх обчислювальних потужностей вже дає штучному інтелекту можливість однаково добре і грати в ігри, і утримувати у токамаках плазму для термоядерного синтезу, і передбачати структури білків. Всі ці перелічені приклади здобутків нейромереж належать розробникам британської компанії DeepMind, які цього разу взялися за історичні письмена і представили алгоритм для відновлення втрачених фрагментів «Ітака».
Як навчити нейромережу розшифровувати тексти?
Названа на честь згаданого в «Одіссеї» грецького острова Ітака (Ithaca) нейромережа навчалася на текстах, написаних давньогрецькою мовою на просторах 84 історичних регіонів Середземномор'я у межах з восьмого століття до нашої ери по восьме століття нашої ери. Для неї цей корпус давньогрецького письма переклали на машиночитний текст включно з символами і словами — всього 78 608 написів, де втрачені, пошкоджені або невідомі слова замінені «тире».
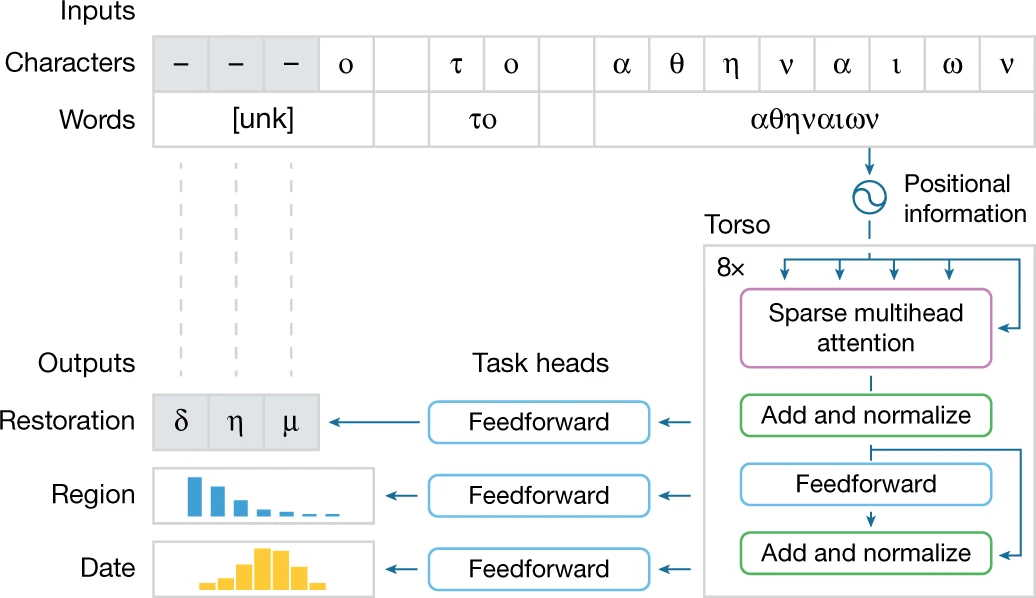
«Ітака» обробляє фразу «δήμο το αθηναίων» («люди Афін»). Перші три символи фрази невідомі, тому «Ітака» сама запропонувала такий варіант відновлення. Yannis Assael et al. / Nature, 2022
Для максимальної користі історикам, архітектура «Ітаки» пропонує вченим не єдиний результат своєї роботи над текстом, а набір з 20 найкращих передбачень, які розподіляє за імовірністю. Щоб віднести текст до певного регіону, «Ітака» також видає свої прогнози стосовно 84 відомих їй географічних областей, а затим розбиває всі дати між 800 роком до нашої ери і 800 роком нашої на 10-річні інтервали, що дає змогу датувати написи з майже 100-відсотковою імовірністю.
Чи задоволені історики «Ітакою»?
Тестування показало, що «Ітака» сама по собі здатна досягти 62-відсоткової точності при відновленні пошкодженого тексту порівняно з 25-відсотковою точністю варіантів, запропонованих експертами. Разом з алгоритмом історики досягли загальної точності 72 відсотки. Крім того, «Ітака» з точністю до 71 відсотка змогла визначити місце походження таксту і датувати його з точністю до 30 років.
За словами розробників, використовувані нейромережею методи, застосовні до всіх дисциплін, що мають справу з давнім текстом: папірологія, кодикологія, палеографія. Причому «Ітаку» можна пристосувати до будь-якої мови (давньої чи сучасної), а також до роботи з додатковими даними, як-то зображення. Команда алгоритму створила загальнодоступний інтерфейс з відкритим вихідним кодом, що дає історикам можливість використовувати «Ітаку» для своїх особистих досліджень, тим самим допомагаючи розвивати її.
Розробники сподіваються, що «Ітака» допоможе історикам звузити широкі або розпливчасті рамки датування, до яких вони іноді змушені вдаватися. Адже попри те, що в «Ітаки» немає стільки контекстуальної інформації, як в істориків, вона має набагато ширші можливості щодо аналізу даних. Тож нейромережа вже отримала можливість продемонструвати свою корисність історикам у тестовому прикладі з набором афінських указів, які були у центрі суперечок щодо часу їх появи. Судячи з форми літер, історики відносили тексти до 446 до нашої ери. Однак така буквена форма використовувалася і після, а текст указів суперечив іншим даним на цьому історичному відрізку часу. У середньому «Ітака» пропонувала датування 421 роком до нашої ери, що збігається з сучасними переоцінками.
Це черговий успіх алгоритмів від DeepMind. Вони стали авторами проривного для науки алгоритму AlphaFold, який передбачив структуру близько 20 тисяч білків, що кодуються людським геномом.Окрім структури білків, нейромережі DeepMind справилися і з прогнозами погоди, та не знаючи жодних правил, пограли у шахи, ґо, 57 ігор на приставці Atari, а також покерували плазмою у справжньому токамаці.





