Менш як половина лікарів-радіологів запідозрила присутність фейків у наборі рентгенівських знімків, де половина зображень була справжньою, а половина — створена за допомогою ChatGPT і RoentGen, спеціальної моделі, тренованої імітувати рентгенівські зображення. Після того як лікарям повідомили, що частину знімків згенеровано, вони змогли визначити діпфейки з точністю до 75 відсотків. Жодна з протестованих моделей штучного інтелекту також не змогла з абсолютною точністю розрізнити згенеровані та справжні зображення. Дослідження опублікували в журналі Radiology.
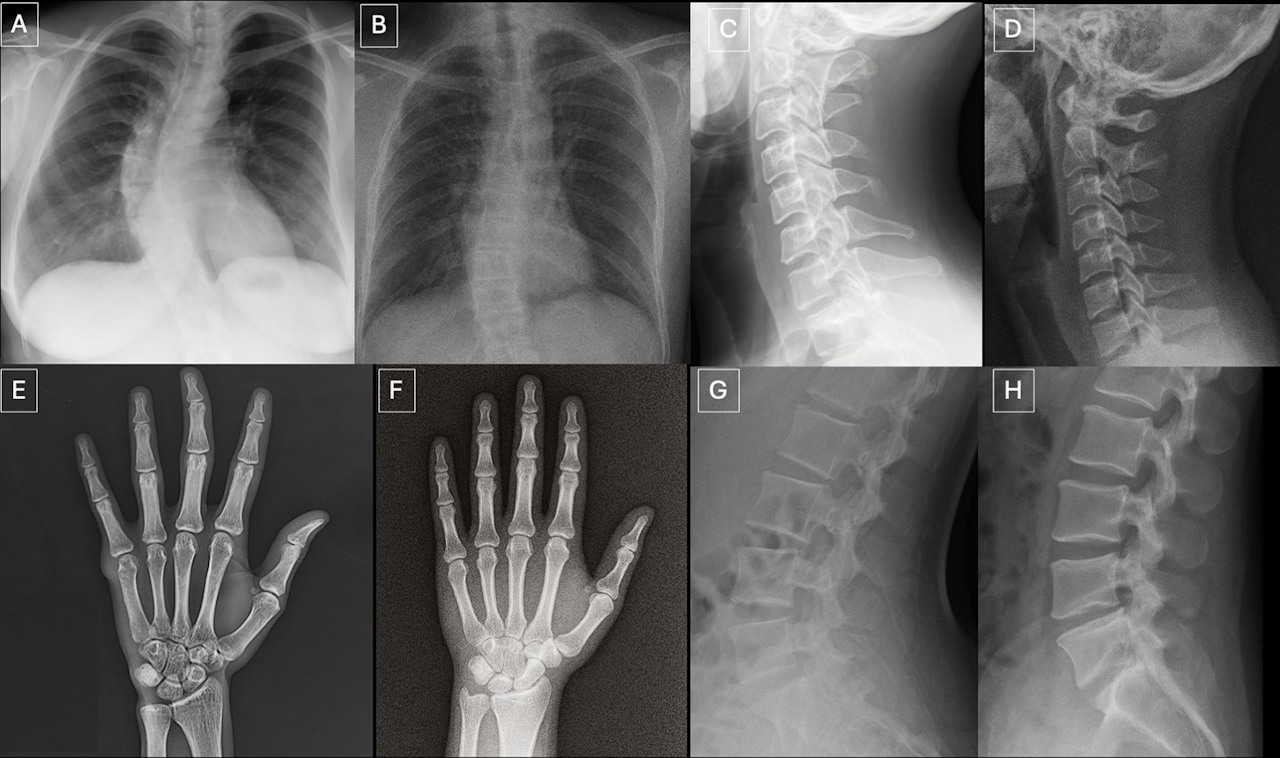
Пари зображень, які показували радіологам. У кожній парі зображення зліва справжнє, а зображення справа — згенероване GPT-4o. Tordjman et al. / Radiology, 2026
Що допомогло лікарям розгледіти фейкові рентген-знімки?
Оскільки моделі штучного інтелекту можуть генерувати все правдоподібніші медичні зображення, це може полегшувати зловмисникам підробку медичної документації. Тому науковці дослідили, з якою точністю лікарі зможуть відрізнити згенеровані зображення від справжніх. 17 радіологів з 12 медичних центрів різних країн отримали завдання описати два набори рентген-зображень. Щодо кожного рентгену лікарі заповнювали коротку форму, у кінці якої вони мали зазначити, чи було на знімку щось незвичне.
Лікарі з більшим досвідом роботи загалом дещо точніше розпізнавали фейки, а гірший результат отримали спеціалісти, які витратили більше часу на опис зображення. Серед ознак, що допомогли відрізнити справжні зображення від штучних, лікарі називали надмірну «ідеальність»: на згенерованих зображеннях сторонні шуми були більш рівномірними, а хребці, легені та галуження судин — більш симетричними, краї зламаних кісток здавалися акуратнішими, краї ребер — рівнішими. Серед моделей штучного інтелекту GPT-4o найкраще шукав фейкові зображення — з точністю 85 відсотків, тоді як успішність Llama 4 Maverick ледь перевищила поріг випадкового вгадування із результатом у 51,8 відсотка.
Які успіхи у використанні штучного інтелекту в медицині
🩻 Те, що досвідчені радіологи краще можуть розгледіти обман, підтвердило й дослідження, де їм показували оптичні ілюзії, — лікарі розпізнали їх краще за студентів.
🙅♀️ А от штучний інтелект, здатний співставляти зображення та текст, усе одно помилився із діагнозами через нерозуміння слова «ні».
😋 ChatGPT і подібні чатботи також не впоралися з плануванням раціону для підлітків з ожирінням і недогодували їх аж на цілих 700 кілокалорій.
💊 Щоб запобігати помилкам штучного інтелекту, науковці навчили його не лестити користувачам, які запитують поради щодо ліків.
🐶 Австралійський айтівець без біологічної освіти використав моделі ChatGPT і AlphaFold, щоб спроєктувати вакцину для свого собаки з раком.