Ця куляста річ, що довго котиться підлогою і підстрибує при киданні — «м'яч». А ось цей кулястий предмет не підстрибує, але смачний і його можна їсти — це «яблуко». Приблизно так вивчають мову немовлята, помічаючи зв'язок між предметом, який бачать, його властивостями, та словом, яке раз за разом повторюють дорослі, вказуючи на нього.
Така здатність дітей вивчати мову, спостерігаючи за зв'язком між предметами, їх властивостями, та словами, викликає захоплення не лише у батьків, а й у науковців. Вона підкреслює складність та ефективність людського мозку. Але чи можливо досягти подібної здатності до навчання у штучного інтелекту? Це питання спонукало групу вчених Нью-Йоркського університету поставити експеримент, який би перевірив, чи здатний штучний інтелект навчитися розуміти світ, спираючись лише на аудіовізуальні дані — як діти.
Для цього науковці використали дані лише у вигляді відео з камери, яку протягом півтора року час від часу носив на голові малюк Сем з Австралії, передаючи програмі дитячий погляд на світ. Розповідаємо, що вийшло у результаті і як це допоможе краще зрозуміти людський розвиток мови та навчання машин.

Малюк Сем з мамою. New York University / YouTube
👋 Слідкуйте за наукою разом з нами — підписуйтеся на наш телеграм та інстаграм, буде цікаво!
Чим відрізняється навчання дітей і машин?
Щоб зрозуміти важливість експерименту, варто розібрати, чим же відрізняється навчання мови у немовлят та алгоритму штучного інтелекту. Традиційно вважається, що діти вчаться через повторення та імітацію, взаємодіючи з батьками та оточенням. Вони формують асоціативні зв'язки між словами та об'єктами, до яких ці слова відносяться, використовуючи контекстуальні підказки для розуміння значення нових слів з раннього віку.

New York University / YouTube
Однак, деталі про те, як саме відбувається формування мовних навичок на ранніх етапах, залишалися недостатньо дослідженими. Деякі науковці припускали, що самого асоціативного навчання недостатньо і вагому роль відіграють вроджені когнітивні здібності людей та складний комплекс навичок і механізмів сприйняття, які сприяють навчанню.
На відміну від дітей, нейромережі зазвичай навчаються на основі величезних обсягів даних, отримуючи чітко визначені пари «зображення-опис», що суттєво відрізняється від більш інтуїтивного та дослідницького підходу дітей. Обсяг інформації, з яким зіштовхуються нейромережі, масштабується до трильйонів одиниць, що набагато перевищує інформаційне навантаження, доступне немовлятам. Ця різниця у підходах та обсязі оброблюваної інформації ключова для розуміння потенціалу та викликів у навчанні — як людей, так і машин. І вона може вказати, чи мають люди складні вроджені механізми для вивчення мови, або ж із її даними навчитися може і комп'ютерна модель.
Як вжили штучний інтелект у роль дитини?
Але вернімося до Сема та науковців. В основу експерименту дослідники поклали унікальний підхід: використання відеоданих, зібраних за допомогою камери, що її з 6 місяців до 2 років час від часу носив на голові малюк. Це дозволило штучному інтелекту зануритися у дитячий досвід, отримавши доступ до візуального та звукового сприйняття світу з погляду хлопчика. Так алгоритм ставав свідком повсякденного життя дитини, включаючи моменти її взаємодії з предметами та спілкування з дорослими.

New York University / YouTube
Попри те, що Сем носив камеру лише близько двох годин на тиждень, реєструючи всього 1 відсоток з його життя, цієї сумарної 61 години записів та 250 тисяч зареєстрованих слів вистачило на створення обширного набору даних для навчання нейромережі.
Алгоритм успішно впорався із завданням навчитися асоціювати слова з візуальними та аудіовізуальними стимулами, які вона зустрічала в даних. На тесті він правильно ідентифікував об'єкти побуту у 62 відсотках випадків — суттєво краще за 25 відсотків, які очікувалися б від випадкового вгадування (яке випливає з чотирьох варіантів вибору, де один вірний). І цей результат порівнянний з аналогічною моделлю, навченою на 400 мільйонах пар зображення-текст.
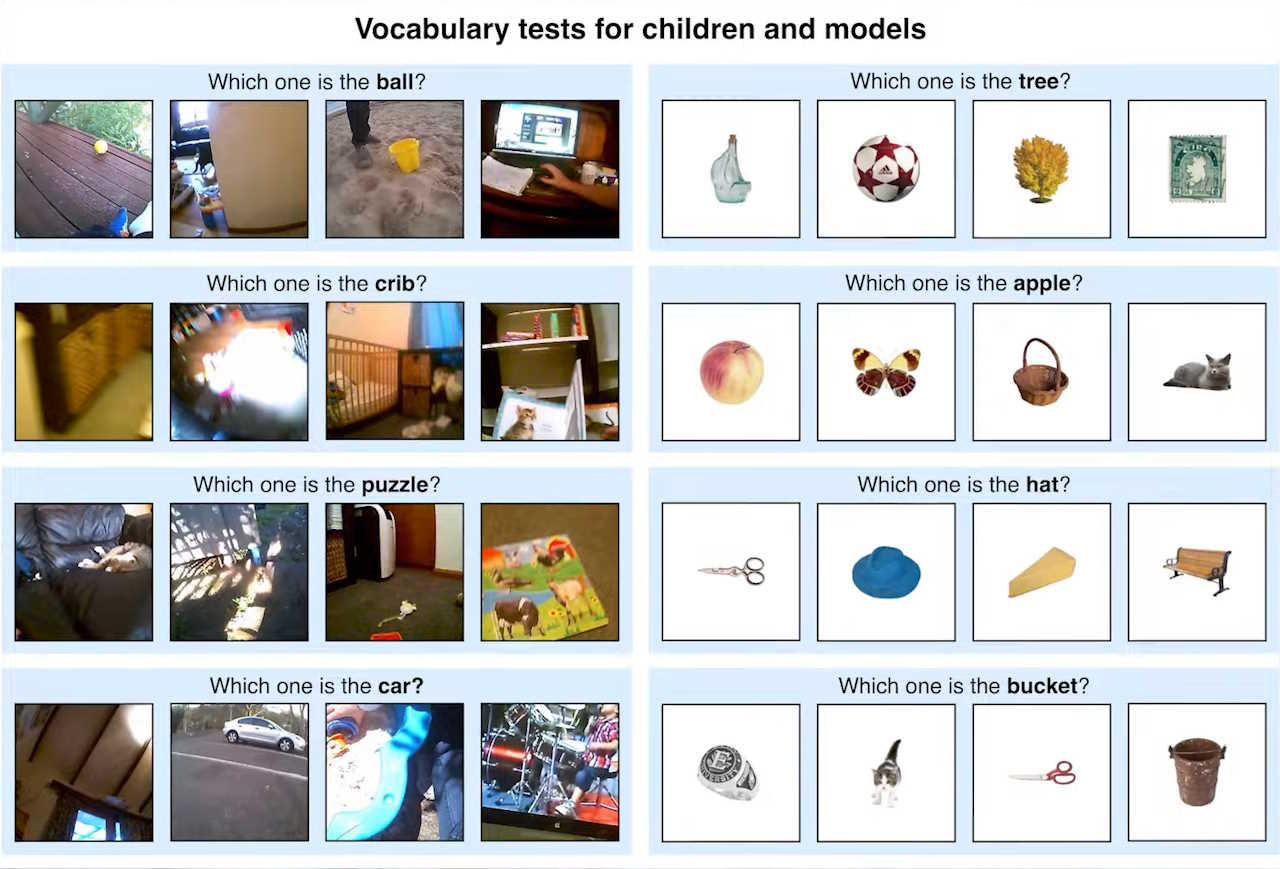
Тести на словниковий запас для дітей та моделей штучного інтелекту. Кожне запитання має чотири відповідних зображення, з яких потрібно обрати те, що відповідає на запитання. Наприклад, «яке є м'ячем?» або «яке зображення є деревом?». New York University / YouTube
Що дав експеримент науці?
Завдяки дослідженню вчені трохи краще зрозуміли, як люди навчаються: схоже, що для набуття мови все ж не потрібно складних вроджених когнітивних механізмів, а досить асоціативного навчання. Водночас експеримент пролив світло на потенціал штучного інтелекту вчитися подібним до людей чином. І він може стати ключем до створення більш інтуїтивно зрозумілих і ефективних алгоритмів. Поглянувши на світ очима дитини, штучний інтелект не лише краще зрозуміє наші команди, але й контекст, в якому вони дані, роблячи взаємодію з технологіями більш природною та ефективною. Так дослідження стає мостом між людським досвідом і майбутнім штучного інтелекту, показуючи, що розуміння одних може збагатити інших.