Фахівці з квантових обчислень Google Quantum AI вперше продемонстрували вигоду від масштабування поверхневого коду квантової корекції помилок. На своєму надпровідниковому квантовому процесорі вони показали, що частота помилок логічних кубітів знизилась при збільшенні кількості фізичних кубітів, які їх складають. Дослідники сподіваються, що їхні результати допоможуть у створенні стійкого до помилок квантового комп'ютера. Робота опублікована у журналі Nature.

Процесор Sycamore від Google. Erik Lucero
Як виправляти помилки кубітів?
Попри те, що фізики не лише знають, які задачі зможуть вирішувати квантові комп'ютери, а і знають, як їх побудувати, практична реалізація обчислювачів на кубітах стикається з низкою проблем. Зокрема до них відноситься чутливість кубітів до навколишнього середовища, вплив якого веде до руйнування квантового стану, а отже і до помилок в обчислюваннях. Одним з підходів захисту кубітів є квантова корекція помилок (quantum error correction), яка заснована на надлишку кубітів.
Ідея полягає в тому, щоб у кодуванні інформації у кількох кубітах, які об'єднують в один логічний кубіт, де частина кубітів зберігає інформацію, а частина — контролює помилки. Повторення інформації дозволяє коду витримувати більшу кількість окремих помилок, оскільки помилки можна контролювати, порівнюючи копії одного і того ж стану кубіта.
Втім, досі кількість помилок від внесення додаткових кубітів, які також піддаються помилкам, перевищувало перевагу від них у виправленні помилок. Але фахівцям Google Quantum AI вдалося довести, що масштабування коду квантового виправлення помилок може бути вигідним.
Що вийшло у Google?
У своєму дослідженні вчені працювали над поверхневим кодом квантової корекції помилок (surface code), що об'єднує в логічний кубіт кілька кубітів, розміщених у шаховому порядку. Кубіти, що несуть дані, розміщені у вершинах кубіти, тоді як кубіти, що контролюють їх, розміщені по краях, як показано на схемі нижче. Така схема дозволяє захищати кубіти від помилок перевороту біта, коли стан кубіта змінюється з 1 на 0 або навпаки, а також від фазових переворотів, коли змінюється знак суперпозиції.
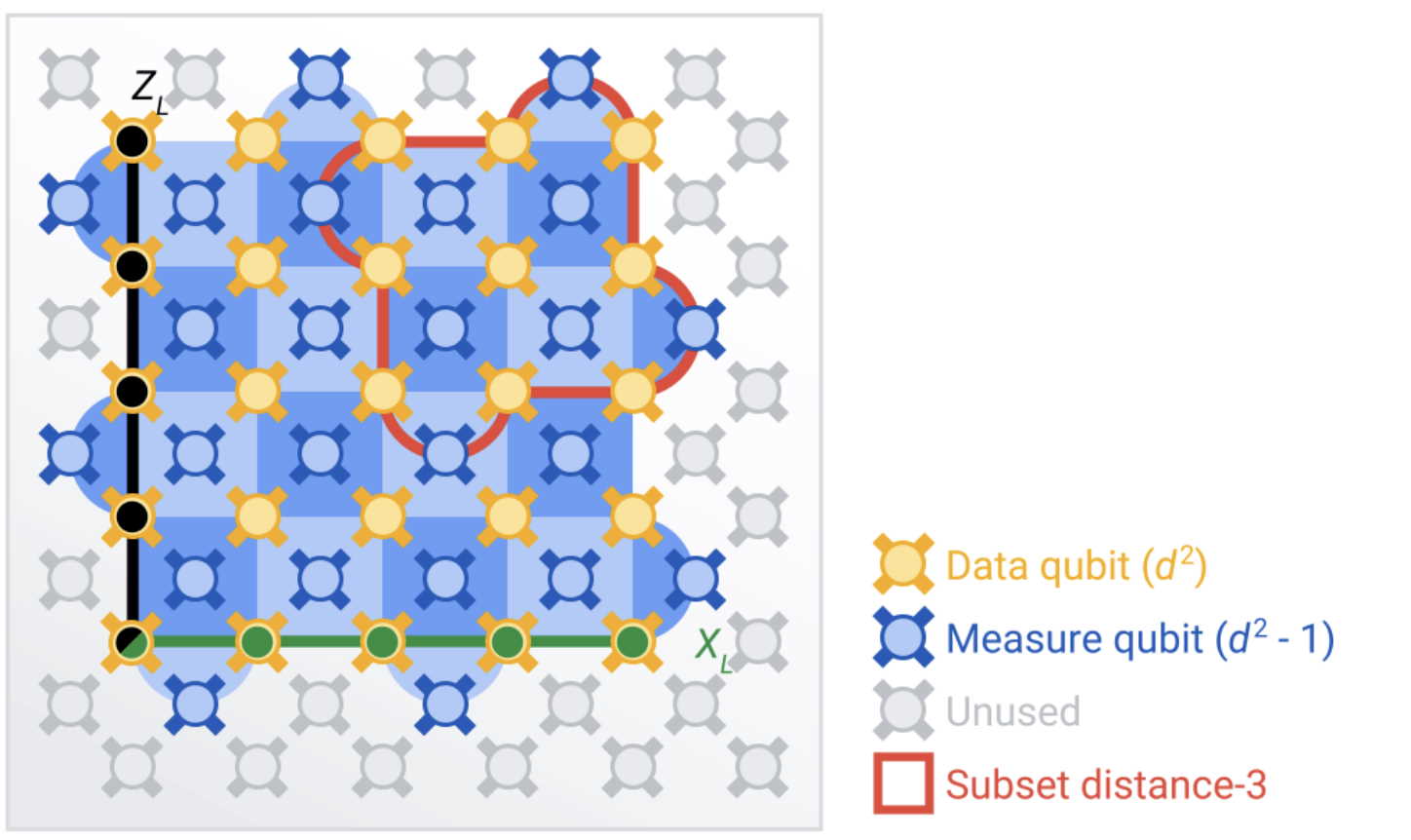
Схема розміщення кубітів для коду корекції помилок, який використали у Google. З 72 кубітів фахівці задіяли 49, де 25 (жовтим) зберігали дані, а 24 — контролювали помилки (синім). Червоним контуром обвели задіяні кубіти для варіанту коду «distance-3». Google Quantum AI / Nature, 2023
Науковці розробили два коди, «distance-3» і «distance-5», які різняться кількістю задіяних кубітів, та випробували їх на 72-кубітному надпровідниковому квантовому процесорі, щоб порівняти ефективність. У першому коді логічний кубіт закодовано у 17 кубітах, де для контролю залучено 8 кубітів. У другому для логічного кубіту використали 49 кубітів, з яких контролюючими були 24.
Щоб порівняти продуктивність кодів, дослідники запускали кілька циклів виправлення помилок, порівнюючи кількість помилок на виході. Так з'ясувалося, що імовірність помилки за один цикл корекції з кодом «distance-5» попри більшу кількість залучених кубітів складає 2,914±0,016 відсотка проти 3,028±0,023 відсотка для коду «distance-3». Це на три відсотки менше попри збільшення кубітів майже втричі. На думку Google Quantum AI, за допомогою такого підходу вони зможуть створити стійкий до помилок квантовий комп'ютер.
Раніше ми розповідали про успіхи у квантовій корекції помилок за допомогою коду Бейкона—Шора, де середня помилка процесора з логічним кубітом з 13 іонних кубітів склала менше відсотка.