Американські інженери представили систему розпізнавання мови, яка не потребує озвучування слів вголос: достатньо відстежувати рух слухового проходу. EarCommand зондує вухо ультразвуком і з допомогою нейромережі конвертує це відлуння в окремі слова та речення. І хоча поки їхня кількість обмежена, помиляється система у 10 відсотках випадків зі словами та у 12 відсотках із реченнями. Роботу представили у Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies.

GIPHY
Як можуть видати вуха?
Більшість розумних побутових пристроїв сьогодні послуговуються керуванням голосом, сприймаючи сказані вголос команди. Однак це супроводжується рядом незручностей: починаючи з того, що на розпізнавання може впливати шум, і завершуючи тим, що така взаємодія з приладами підіймає питання конфіденційності. Звісно, можна послуговуватися читанням по губах, що вимагає камер. Однак дослідники університету штату Нью-Йорк у Баффало та інших американських інститутів обрали набагато зручніший з точки зору комфорту користувача підхід — читання по деформації слухового проходу під час говоріння, що потребує вже звичних навушників, але не вимагає говоріння вслух.
Під час говоріння задіяні понад 70 м'язів обличчя і шиї, а також кісток, які здатні деформувати і рухати слуховий прохід (Ear Canal Dynamic Motion). І автори роботи взялися за виявлення цих деформацій, розрізнення їх від інших дій окрім говоріння, а також, звичайно, перетворення їх на окремі слова та речення — команди для системи EarCommand.
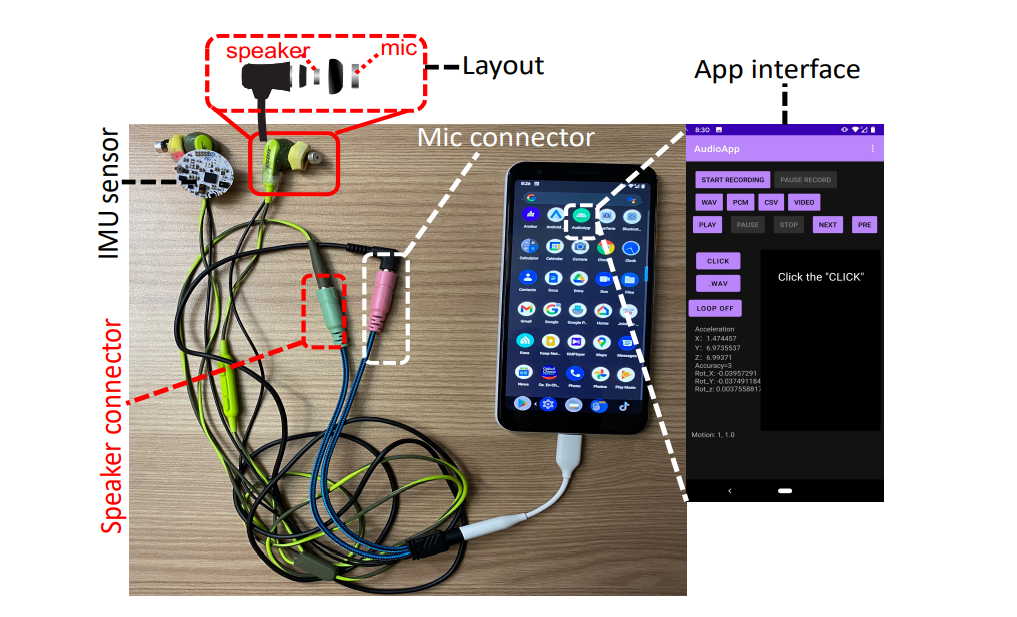
Необхідне обладнання. Yincheng Jin et al. / Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., 2022
Як читати по вухах?
Користувацька частина EarCommand складається за смартфона і навушників, які мають ним керувати. Вони включають і динамік, і мікрофон, а також невеликий стандартний датчик IMU для розпізнавання рухів голови — це потрібно, щоб вмикати і вимикати систему для економії заряду. Достатньо кивнути головою, щоб вмикнутися, а щоб вимкнути — похитати голову з боку в бік. Коли користувач надягає навушники та вмикає EarCommand, звернений всередину вуха динамік починає працювати на рівні гучності у 50 децибелів. Відлуння цього звуку сприймає мікрофон, а отримані ехо-сигнали нейромережа розшифровує і вже передає свій висновок назад на смартфон у вигляді певної команди: наприклад, «зменшити гучність».
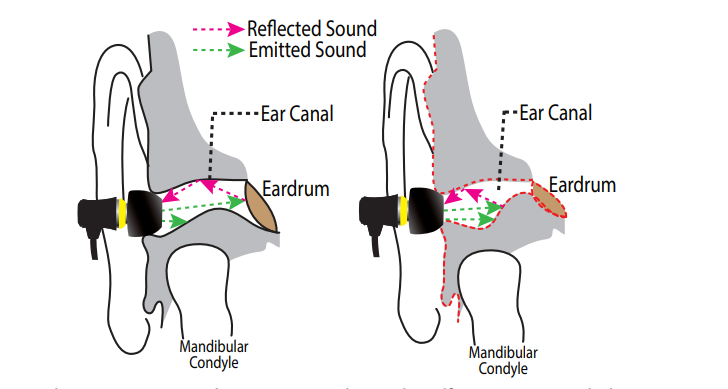
Схема роботи системи. Yincheng Jin et al. / Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., 2022
Розшифровувати різницю між статичним положенням вушного каналу та його змінами під час говоріння дослідники вирішили за допомогою згорткової нейронної мережі. Вона аналізує патерни відбитих звукових хвиль з динаміка у навушниках, пов'язує їх із дефомацією форми слухового проходу, а відтак і з окремими словами. Всього її навчили розпізнавати 32 команди з окремих слів та 25 речень-команд, як-то «відповісти» чи «зателефонувати мамі». Користувачу при цьому нема необхідності говорити їх вслух — лише пошепки.
Які слова впізнала нейромережа?
У розпізнаванні команд з одного слова EarCommand помилялася у 10 відсотках випадків, а в інтерпретації речень — у 12. Втім, вчені сподіваються зібрати більше зразків слів і речень для навчання, щоб знизити рівень помилок, а також пропонують користувачам самостійно навчати систему, індивідуалізуючи її навички під час користування. Порівнюючи EarCommand з іншими системами, автори роботи зазначають, що порівняно із системами, наприклад, на основі камер, EarCommand має перевагу у захисті конфіденційності та може використовуватися у громадських місцях. Також не потрібні жодні жести, що звільняє руки, і словниковий запас системи, звісно, більший, ніж подібні, засновані на рухах, наприклад, голови.
Різні шаблони руху слухового каналу під час промовляння різних слів. Yincheng Jin et al. / Proc. ACM Interact. Mob. Wearable Ubiquitous Technol., 2022
Ми вже розповідали про таку технологію, тільки для розпізнавання емоцій, а не слів. Подібний сонар у вигляді навушників може за відлунням стежити за рухами обличчя і так відрізняти нахмурене чоло від посмішки.
Що про вас скажуть нейромережі?
🥳 За кардіограмою нейромережа може впізнати радість і сум
🧘🧦За тиском на розумні шкарпетки впізнає позу йоги
👌А через пов'язку на руку може зрозуміти, який ви показуєте жест